cqdm
Let’s speed up the popular tqdm library with a Python C Extension!
Python’s high level of abstraction makes it an excellent language for succinctly writing complex code. But that convenience comes at a cost: compared to native code, pure Python can be orders of magnitude slower. Luckily, the CPython interpreter supports C-Extensions. These are natively compiled modules that allow Python to call performant C code. Almost every data science (numpy, scipy) or machine learning (tensorflow) package uses C-Extensions to get sensible levels of performance. And these use cases make a lot of sense, because they’re performing big, expensive computations (like multiplying two large matrices). But can we also use C-Extensions to optimize small, cheap functions? In this post, I’ll detail my progression to a 4.5x speed up of the popular tqdm library.
Background
I love optimization, and I’ve always wanted to learn to write Python C-Extensions. I wanted to explore optimizing Python code using a C-Extension. But I was curious about the overhead of C-Extensions, and if they could be used to speed up well-written, simple code. Code that was only a few short statements, but potentially called millions of times.
I decided to focus on optimizing a popular library called tqdm. In its own words,
tqdm is a fast, extensible progress bar for Python and CLI. To summarize its behavior, tqdm exposes a class tqdm
that can wrap any iterable. Then, when you iterate through the wrapper, it displays a progress bar. Here’s
an example:
from tqdm import tqdm
for i in tqdm(range(10000)):
do_stuff(i)This would draw a bar similar to:
76%|████████████████████████ | 7568/10000 [00:33<00:10, 229.00it/s]The package is widely used, with over 43 million monthly downloads, and it advertises a “low overhead” of 60ns per iteration. Let’s get started.
Profiling
We begin by running Python’s cProfiler on the following script:
for i in tqdm.tqdm(range(50_000_000)):
pass
The vast majority of time is spent within tqdm.__iter__. Once inside tqdm.__iter__, only 0.5% of time is spent
calling other functions. That means the overhead (at least in this silly testcase) lies almost entirely inside
tqdm.__iter__.
The tqdm.format_meter function is the one that actually draws the progress bar. It’s interesting that this is only
called 138 times, using 9 milliseconds out of 13.7 seconds. To understand how that’s possible, let’s take a look at
the source of tqdm.__iter__:
def __iter__(self):
# Inlining instance variables as locals (speed optimisation)
iterable = self.iterable
# If the bar is disabled, then just walk the iterable
# (note: keep this check outside the loop for performance)
if self.disable:
for obj in iterable:
yield obj
return
mininterval = self.mininterval
last_print_t = self.last_print_t
last_print_n = self.last_print_n
min_start_t = self.start_t + self.delay
n = self.n
time = self._time
try:
for obj in iterable:
yield obj
# Update and possibly print the progressbar.
# Note: does not call self.update(1) for speed optimisation.
n += 1
if n - last_print_n >= self.miniters:
cur_t = time()
dt = cur_t - last_print_t
if dt >= mininterval and cur_t >= min_start_t:
self.update(n - last_print_n) # render to terminal
last_print_n = self.last_print_n
last_print_t = self.last_print_t
finally:
self.n = n
self.close()This function is a generator, executing code for every item yielded from the wrapped iterable. The highlighted line
shows a call to self.update, which calls self.format_meter and prints the bar. This line is only reached if a
bunch of conditions are met. These conditions give tqdm its high performance. It only draws the bar if self.miniters
iterations have passed, and self.mininterval seconds have passed. Our goal is to speed up these two checks using a
C-Extension.
Writing a C extension
To get familiar with C-Extensions, we start simple. Let’s create a type yielder that behaves identically to the
following class:
class yielder:
def __init__(self, iterable):
self.iterable = iterable
def __iter__(self):
for i in self.iterable:
yield iWe’ll make use of the official C-Extension tutorial and documentation.
We begin by defining a struct Yielder that holds the information our yielder needs. In this case, that’s just
a reference to an iterator, which we’ll create from the iterable:
#include <Python.h>
typedef struct {
PyObject_HEAD;
PyObject *iterator;
} Yielder;We define the yielder constructor as yielder_new:
static PyObject *yielder_new(PyTypeObject *type, PyObject *args,
PyObject *kwargs) {
PyObject *iterable;
if (!PyArg_UnpackTuple(args, "yielder", 1, 1, &iterable)) {
return NULL;
}
PyObject *iterator = PyObject_GetIter(iterable);
if (!iterator) {
return NULL;
}
YielderState *yielder = (Yielder *)type->tp_alloc(type, 0);
if (!yielder) {
return NULL;
}
yielder->iterator = iterator;
return (PyObject *)yielder;
}This constructor does a few things. First, it accepts a single argument and saves it as iterable. Then it
creates iterable using PyObject_GetIter, which is equivalent to Python’s iter builtin. Lastly it allocates
a new instance of a yielder, saves our reference to iterator, and returns.
To make our yielder type an iterable, we need to define a tp_iternext method. Ours is simple:
static PyObject *yielder_next(Yielder *yielder) {
PyObject *item = PyIter_Next(yielder->iterator);
if (item == NULL) {
// Iterator exhausted. Return NULL to signal we're exhausted.
return NULL;
}
return item;
}This works because the iterator keeps track of its position within the underlying iterable. We simply keep
returning the next item until there are no more items.
To finish our type methods, we define yielder_dealloc:
static void yielder_dealloc(Yielder *yielder) {
Py_XDECREF(yielder->iterator);
Py_TYPE(yielder)->tp_free(yielder);
}Now we define the yielder type using these methods:
PyTypeObject PyYielder_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
.tp_name = "yielder",
.tp_basicsize = sizeof(Yielder),
.tp_dealloc = (destructor)yielder_dealloc,
.tp_flags = Py_TPFLAGS_DEFAULT,
.tp_iter = PyObject_SelfIter,
.tp_iternext = (iternextfunc)yielder_next,
.tp_alloc = PyType_GenericAlloc,
.tp_new = yielder_new,
};Our type is an iterator because it defines tp_iternext (used by the next builtin). And if something calls iter on
our type, it returns itself because we set tp_iter to PyObject_SelfIter. This should give us the behavior we want.
For completion, here’s a little more C boilerplate to set up our yielder_native module:
static struct PyModuleDef yieldermodule = {
PyModuleDef_HEAD_INIT,
.m_name = "yielder_native",
.m_size = -1,
};
PyMODINIT_FUNC PyInit_yielder_native(void) {
PyObject *m;
m = PyModule_Create(&yieldermodule);
if (m == NULL) {
return NULL;
}
if (PyType_Ready(&PyYielder_Type) < 0) {
return NULL;
}
Py_INCREF((PyObject *)&PyYielder_Type);
PyModule_AddObject(m, "yielder", (PyObject *)&PyYielder_Type);
return m;
}We’ve put all this code in yielder.c. We can create a simple setup.py to let us compile and install our
C-Extension:
from setuptools import Extension, setup
yielder_native = Extension(
"yielder_native",
sources=["yielder.c"],
)
setup(
name="yielder",
ext_modules=[yielder_native],
)Now we’re ready to rumble. After building and installing, we can verify behavior, and test performance:
from yielder_native import yielder
iterable = [1, 2, 3, "a", "b", "c"]
assert iterable == list(yielder(iterable))
for _ in yielder(range(50_000_000)):
passThe yielder works! Benchmarking against tqdm, we’re seeing an 8x speedup. Since this yielder doesn’t do any
progress bar update checks, 8x is our maximum possible speed up.
Now we need to add to our yielder to make it closer to tqdm. Luckily, we can take a few shortcuts, and don’t
need to rewrite the entirety of tqdm in C.
Integrating with tqdm
If you recall, tqdm.__iter__ was a relatively simple function. The complexity of tqdm lies within the tqdm.update
function. Luckily, it turns out that you can
call Python functions from C. That means that if our
yielder keeps a reference to some tqdm object, it can call tqdm.update. Specifically, we’ll want to overwrite
the existing tqdm.__iter__ function to simply defer to our native yielder, passing a reference to self which we
can use to call self.update as needed.
Of course, in order to know when to call self.update, we’ll want to track a bunch of state in our yielder. Let’s
take another look tqdm.__iter__, with some annotations:
def __iter__(self):
# These would become part of our Yielder struct
iterable = self.iterable
mininterval = self.mininterval
last_print_t = self.last_print_t
last_print_n = self.last_print_n
min_start_t = self.start_t + self.delay
n = self.n
# We'd also save a reference to self
try:
for obj in iterable:
yield obj
n += 1
if n - last_print_n >= self.miniters:
cur_t = time()
dt = cur_t - last_print_t
if dt >= mininterval and cur_t >= min_start_t:
self.update(n - last_print_n) # call self.update using the reference to self
last_print_n = self.last_print_n
last_print_t = self.last_print_t
finally:
# This runs when the iterator is finished
self.n = n # set self.n using the reference to self
self.close() # call self.close using the reference to selfSo our first step will be to modify our struct Yielder to have the additional state we need to track:
typedef struct {
PyObject_HEAD;
PyObject *tqdm_obj; // self
PyObject *iterator;
double mininterval;
double last_print_t;
long last_print_n;
double min_start_t;
long n;
} Yielder;And we want to update our yielder_new to take in a tqdm instance, and set our values accordingly. This gets a
little verbose with the error checking:
static PyObject *yielder_new(PyTypeObject *type, PyObject *args, PyObject *kwargs) {
PyObject *tqdm_obj; // self
if (!PyArg_UnpackTuple(args, "yielder", 1, 1, &tqdm_obj)) {
return NULL;
}
CqdmState *yielder = (Yielder *)type->tp_alloc(type, 0);
if (!yielder) {
return NULL;
}
PyObject *iterable = PyObject_GetAttrString(tqdm_obj, "iterable");
if (!iterable) {
return NULL;
}
PyObject *iterator = PyObject_GetIter(iterable);
if (!iterator) {
return NULL;
}
PyObject *mininterval = PyObject_GetAttrString(tqdm_obj, "mininterval");
if (!mininterval || !PyFloat_Check(mininterval)) {
return NULL;
}
yielder->mininterval = PyFloat_AsDouble(mininterval);
PyObject *last_print_t = PyObject_GetAttrString(tqdm_obj, "last_print_t");
if (!last_print_t || !PyFloat_Check(last_print_t)) {
return NULL;
}
yielder->last_print_t = PyFloat_AsDouble(last_print_t);
PyObject *last_print_n = PyObject_GetAttrString(tqdm_obj, "last_print_n");
if (!last_print_n || !PyLong_Check(last_print_n)) {
return NULL;
}
yielder->last_print_n = PyLong_AsLong(last_print_n);
PyObject *start_t = PyObject_GetAttrString(tqdm_obj, "start_t");
if (!start_t || !PyFloat_Check(start_t)) {
return NULL;
}
PyObject *delay = PyObject_GetAttrString(tqdm_obj, "delay");
if (!delay) {
return NULL;
}
yielder->min_start_t = PyFloat_AsDouble(PyNumber_Add(start_t, delay));
PyObject *n = PyObject_GetAttrString(tqdm_obj, "n");
if (!n || !PyLong_Check(n)) {
return NULL;
}
yielder->n = PyLong_AsLong(n);
// If we get through all those checks, things are looking good.
// Let's INCREF the objects, and save them.
Py_INCREF(tqdm_obj);
yielder->tqdm_obj = tqdm_obj;
Py_INCREF(iterator);
yielder->iterator = iterator;
return (PyObject *)yielder;
}Accessing a field is fairly simple using something like PyObject_GetAttrString(tqdm_obj, "mininterval"). This returns
a PyObject*, but we can convert to C double using PyFloat_Check and PyFloat_AsDouble. Saving as a raw double
or long will make our operations a lot faster.
At this point, we’ll have a yielder instance that stores the state of tqdm.__iter__. Now we can take a crack at
rewriting those comparisons within the for loop. We update our yielder_next method:
static PyObject *yielder_next(Yielder *yielder) {
PyObject *item = PyIter_Next(yielder->iterator);
if (item == NULL) {
// Iterator exhausted. Run the finally block
PyObject *n = PyLong_FromLong(yielder->n);
PyObject_SetAttrString(yielder->tqdm_obj, "n", n);
Py_XDECREF(n);
PyObject *close = PyObject_GetAttrString(yielder->tqdm_obj, "close");
PyObject_CallNoArgs(close);
// Then return NULL to signal we're exhausted.
return NULL;
}
yielder->n++;
// Get the value of self.miniters (it's a float or an int)
long miniters = 0;
PyObject *miniters_obj = PyObject_GetAttrString(yielder->tqdm_obj, "miniters");
if (PyLong_Check(miniters_obj)) {
miniters = PyLong_AsLong(miniters_obj);
} else if (PyFloat_Check(miniters_obj)) {
miniters = (long)PyFloat_AsDouble(miniters_obj);
}
if (yielder->n - yielder->last_print_n >= miniters) {
// Get the current time in seconds as a double
// Equivalent to Python's time.time()
struct timespec ts;
clock_gettime(CLOCK_REALTIME, &ts);
double cur_t = ts.tv_sec + (ts.tv_nsec * 1e-9);
double dt = cur_t - yielder->last_print_t;
if (dt >= yielder->mininterval && cur_t >= yielder->min_start_t) {
// Call self.update(n - last_print_n)
PyObject *update_func = PyObject_GetAttrString(yielder->tqdm_obj, "update");
PyObject *args = Py_BuildValue("(i)", yielder->n - yielder->last_print_n);
PyObject_Call(update_func, args, NULL);
Py_XDECREF(args);
// Update last_print_t and last_print_n
PyObject *last_print_t = PyObject_GetAttrString(yielder->tqdm_obj, "last_print_t");
yielder->last_print_t = PyFloat_AsDouble(last_print_t);
PyObject *last_print_n = PyObject_GetAttrString(yielder->tqdm_obj, "last_print_n");
yielder->last_print_n = PyLong_AsLong(last_print_n);
}
}
return item;
}We have to fetch a few fields from self using PyObject_GetAttrString and our reference. We also have to
use the clock_gettime syscall to get the current time (this is how CPython’s time.time() does it too).
We make a minor update to yielder_dealloc to decrement our tqdm reference:
static void yielder_dealloc(Yielder *yielder) {
Py_XDECREF(yielder->tqdm_obj);
Py_XDECREF(yielder->iterator);
Py_TYPE(yielder)->tp_free(yielder);
}And that’s it, we can go back to Python. To override tqdm.__iter__ we create a subclass of tqdm called cqdm:
from tqdm import tqdm
from yielder_native import yielder
class cqdm(tqdm):
def __iter__(self):
if self.disable:
for obj in iterable:
yield obj
return
yield from yielder(self)Believe it or not, that’s all we need. We can test it out with:
for i in cqdm(range(50_000_000)):
passUnfortunately, when compared tqdm, we only see a 1.15x speedup… Why?
Speeding It Up
There’s an interesting comment at the top of the original __iter__ function:
# Inlining instance variables as locals (speed optimisation).We’ve moved most of the instance variables into our struct Yielder, but not all of them. We haven’t moved
self.miniters, mainly because tqdm doesn’t move it either. We’re calling PyObject_GetAttrString every iteration
to get the value of miniters. Could this be slowing us down? To test, we can comment out the access in
yielder_next and set it to a hardcoded value. Sure enough, we start getting a respectable 3x speed up.
Unfortunately, there’s a reason tqdm doesn’t inline self.miniters. As an optimization, tqdm only checks certain
conditions (calling time()) every self.miniters iterations. self.miniters is updated inside self.update.
This optimization works fine if the iterations take similar amounts of time, but if they suddenly slow down,
the progress bar would freeze. To get around this, tqdm has a monitoring thread that checks the progress of each bar
in the background, and changes self.miniters if they’re slowing down. So we really do need to be monitoring
the miniters of the tqdm object within our yielder.
If we converted it to a field in our C struct (making it “inlined” like the other attributes), the monitoring
thread wouldn’t be able to change it. But what if we also added a new method to our C Extension that can change
the value of miniters, and somehow replaced attempts to set miniters with a call to this method. That should work.
We’ll add a long miniters field to our struct Yielder, and set it in yielder_new.
Then we can add a new yielder_set_miniters method to our C code:
static PyObject *yielder_set_miniters(Yielder *yielder, PyObject *miniters) {
if (!miniters) {
return NULL;
}
if (PyLong_Check(miniters)) {
yielder->miniters = PyLong_AsLong(miniters);
} else if (PyFloat_Check(miniters)) {
yielder->miniters = (long)PyFloat_AsDouble(miniters);
} else {
return NULL;
}
Py_RETURN_NONE;
}We also need to update our type definition to add the set_miniters method to the yielder type:
static PyMethodDef yielder_methods[] = {
{"set_miniters", (PyCFunction)yielder_set_miniters, METH_O,
"Set miniters (used by tqdm monitor thread)"},
{NULL} /* Sentinel */
};
PyTypeObject PyYielder_Type = {
/* ... */
.tp_methods = yielder_methods,
};On the Python side, it’s fairly easy to modify the cqdm class to use our new C function by overriding __setattr__:
class cqdm(tqdm):
def __setattr__(self, key, value):
super(cqdm, self).__setattr__(key, value)
if key == "miniters" and hasattr(self, "_yielder"):
self._yielder.set_miniters(value)
def __iter__(self):
if self.disable:
for obj in self.iterable:
yield obj
return
self._yielder = yielder(self)
yield from self._yielderRunning a performance test again, this gave us a 3x speedup, while preserving the functionality of self.miniters.
One Last Optimization
A 3x speed up is pretty good. But there was one last optimization to try.
__iter__ needs to return an iterator. It can do this by being a generator (meaning it has yield or yield from
statements), or returning an iterator. By using yield from, we are turning __iter__ into a generator.
Let’s modify __iter__ to directly return our yielder:
def __iter__(self):
if self.disable:
return iter(self.iterable)
self._yielder = yielder(self)
return self._yielderThis minor change increased our speedup from 3x to 4.5x.
After a few more changes, such as inlining self.update and adding error checks, we can generate the following
performance graph:
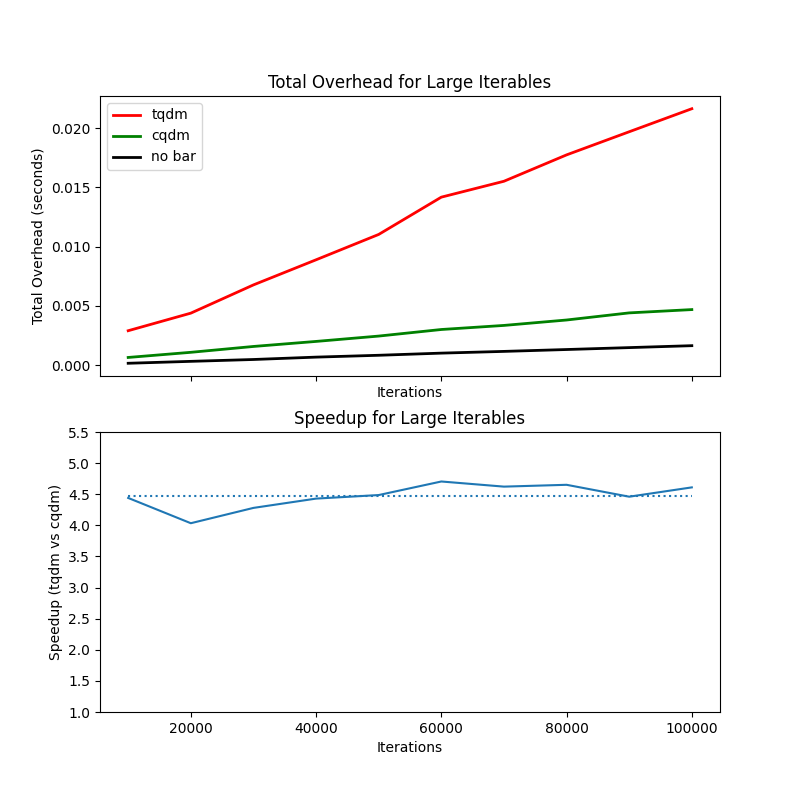
Finishing Up
The project is available on GitHub. It’s also available
on PyPI as cqdm thanks to the manylinux
project.
For fun, in the README, I calculate the impact cqdm would have if adopted globally:
There are over 40 million monthly downloads of tqdm. Let’s assume there are 40 million instances of tqdm running every day, each performing 100,000 iterations. This totals 92,000 seconds or 9.58 days of overhead, per day. Using a reasonable price for CPU time on AWS, this equates to around $10 of compute, per day globally.
Switching to cqdm would reduce this overhead by 4/5. That means, if everyone switched to using cqdm, we could save $8 in CPU time per day, globally.
Of course, this ignores the increased time for installs, compilation, etc., which is likely orders of magnitude greater than the time saved…
In conclusion, optimizing tqdm with C Extensions was possible, but not trivial. I needed a deep understanding of how the library and CPython worked. It was an interesting academic exercise, but the benefits were small. Similar optimization attempts are probably never worth it. If this amount of time-saved (0.002 seconds saved over 100,000 iterations) matters to a project, it shouldn’t be written in Python in the first place.